Mens databaserte metoder de siste tiårene har vært brukt for å kalkulere kjemiske reaksjoner, har Maarten Beerepoot kommet ett skritt lenger gjennom realistiske beregninger av mekanismer, i store biologiske molekyler.
Bruker selvlysende protein for å bekrefte datamodell
Et selvlysende protein fra en manet forteller forskeren om han bommer totalt på sine databeregninger.
UiT Norges arktiske universitetUiTNorges arktiske universitet
Kjemiske forsøk på laben kan være både tidkrevende, dyre og risikofylte. I tillegg har de gjerne en del praktiske begrensninger som ikke finnes i datamodeller.
Maarten Beerepoot har i sin forskning jobbet med teoretiske kjemiforsøk.
Han har utviklet en ny metode som får teoretiske datamodeller til å likne virkelige prosesser i molekyler.
Metoden har han testet ut på et stort protein.
Dette ble gjort ved å se på samsvar mellom simuleringer i datamodellen og faktiske forsøk på laboratoriet.
Årsaken til at Beerenpoot utviklet en ny metode, er at de gamle metodene bare fungerer fint på mindre og enklere molekyler, som for eksempel et vannmolekyl.
Men en molekylmodell blir fort veldig kompleks og det blir dermed kostbart å beregne krefter i et stort biologisk molekyl, som et protein er.
Særlig siden modellen også skal beskrive det kjemiske samspillet inne i cellen.
– Virkeligheten er veldig kompleks, sier Beerepoot.
De vanligste metodene for teoretiske kjemiforsøk på større molekyler fremstiller en forenklet virkelighet.
– Vi har forsøkt å finne ut mer om hvordan vi skal skrive inn realistiske omgivelser i de teoretiske forsøkene våre, sier forskeren.
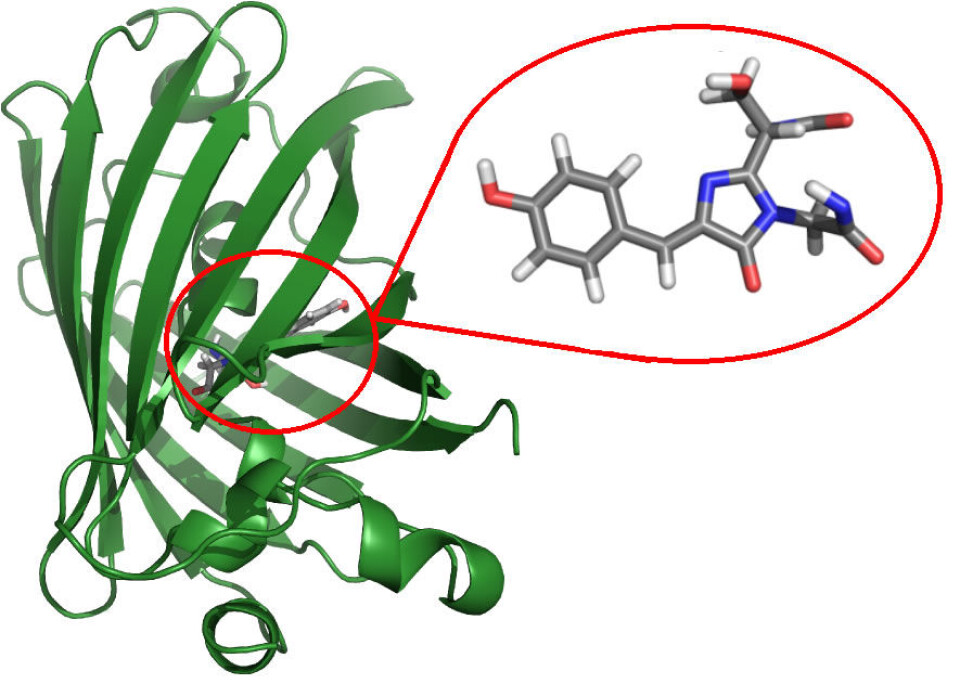
Beerepoot brukte datamodeller for å beregne hva som skulle til for å endre proteinet fra å lyse grønt til å lyse gult/blått. Figuren viser oppbygningen til GFP og hvor i proteinet forskerne kan gjøre endringer for å få til de fascinerende fargeskiftene. (Foto: Arnfinn Hykkerud Steindal/UiT)
Som følge av den store kompleksiteten har selv ikke de største datamaskinene regnekraft til å utføre en 100 prosent nøyaktig beskrivelse, forteller han videre.
– Se bare for deg hvor kraftig verktøyet må være om datamaskinen skal beregne hvordan medisiner oppfører seg i kroppene våre eller hvordan forurensning påvirker plante- og dyreliv i naturen. Men med vår metode forsøker vi å komme så nær virkeligheten som mulig, forklarer han.
Men forskerne har ennå ikke verktøy til å kunne modellere hele samspillet av molekyler inne i en hel celle.
– Vår metode kan likevel beskrive enkelte mekanismer inne i et stort protein. Vi har brukt et velkjent protein i forskningsverden for å teste om beregningene våre holder vann, sier han.
Proteinet forskeren bruker, blir produsert på laboratoriet.
Green fluorescence protein (GFP) kommer opprinnelig fra maneter som lyser i mørket på dyphavet.
Dette selvlysende proteinet har blitt mye brukt for å fargelegge prosessene i kroppens celler.
– Vi har altså brukt et godt synlig protein for å se om våre teoretiske beregninger lar seg bekrefte med eksperimenter på laboratoriet, forteller han.
GFP brukes i medisinsk forskning blant annet fordi den kraftige selvlysende fargen gjør at stoffer som har fått en GFP-lapp på seg, er lette å lokalisere inne i cellene. I et mikroskop kan forskerne følge med om for eksempel medisin når frem til riktig sted i syke celler.
Beerepoot brukte GFP fordi proteinet er såpass stort og kompleks at det ville utfordre metoden hans.
I et protein er atomers plassering underlagt et sett med fysiske lover, som benyttes i datamodellen for å estimere hvordan endringene arter seg.
Dersom forskeren bytter ut én aminosyre, byggesteinen i proteinet, vil en god modell kunne beregne konsekvensene av endringene i hele molekylet.
Ved å endre den genetiske koden på en bestemt måte skifter han det opprinnelig grønne proteinet til å lyse gult eller blått.
Dette byttet gjør at hele eller deler av proteinet endrer form til et blått molekyl, slik at det nå lyser blått og ikke grønt.
Annonse
Maarten Beerepoot er fra Wageningen i Nederland og har i tillegg til sin kjemiutdanning, en Master of Arts ved Universitetet i Leiden i Nederland. (Foto: Vibeke Os/UiT)
I datamodellen av GFP-proteinet har Beerepoot forsøkt å få til de samme endringene. Lyser det blått, bekrefter det at modellen fungerer. Og dermed kan datamodellens teoretiske oppskrift brukes praktisk i andre sammenhenger i laboratoriet.
Ifølge Beerepoot har de klart å få godt samsvar mellom databeregningene og de eksperimentelle forsøkene, noe som igjen er et steg videre i prosessen med å utarbeide mer realistiske teoretiske beregninger.
De fleste biologiske reaksjoner påvirkes på en aller annen måte av det miljøet de befinner seg i, for eksempel det salte havet, den sure magesekken, den oksygenfattige myren eller i en fettholdig membran i cellene.
– Vi jobber med å utvikle modeller som skal beskrive virkeligheten så nøyaktig som mulig, og må hele tiden overveie kompleksitet og datakraft mot grad av nøyaktighet, avslutter Beerepoot.
Referanse:
Maarten Beerepoot. Calculating molecular properties in realistic environments. Doktorgradsavhandling ved Universitetet i Tromsø. 2016. Sammendrag.