Denne artikkelen er over ti år gammel og kan inneholde utdatert informasjon.
(Figur: Videnskab.dk, oversatt av forskning.no)
PISA-undersøkelsen munner blant annet ut i en rankingliste som viser hvordan elevene i 70 forskjellige land klarer seg. Men forskerne bak testen redegjør ikke for hvordan den er laget.
Det mener den danske statistikeren Svend Kreiner fra Institut for Biostatistik på Københavns Universitet.
I et forsøk på å forstå hvordan modellen virker har han nylig gjennomgått de tekniske rapportene bak testen.
– Forskerne bak PISA bruker datamaskiner til å skape modellen sin, men det er svært uklart hvordan den arbeider, sier Kreiner til Videnskab.dk.
- Modellen består av mange delkomponenter som for uteforstående fremstår som svarte bokser; man kaster inn noen tall, uten at man kan forstå hva boksene inneholder og det de gjør med tallene.
- Datamodellen ligger altså i mørket. Det er dypt kritikkverdig når rankinglisten spiller en så stor rolle for utviklingen av utdanningssystemet, sier Kreiner.
Kjønn, alder og sosial status spiller en rolle
De delkomponentene som faktisk er beskrevet i rapportene, er Kreiner også skeptisk til.
Han kaster seg ut i en gjennomgang av modellen i et forsøk på å demonstrere hva som er galt:
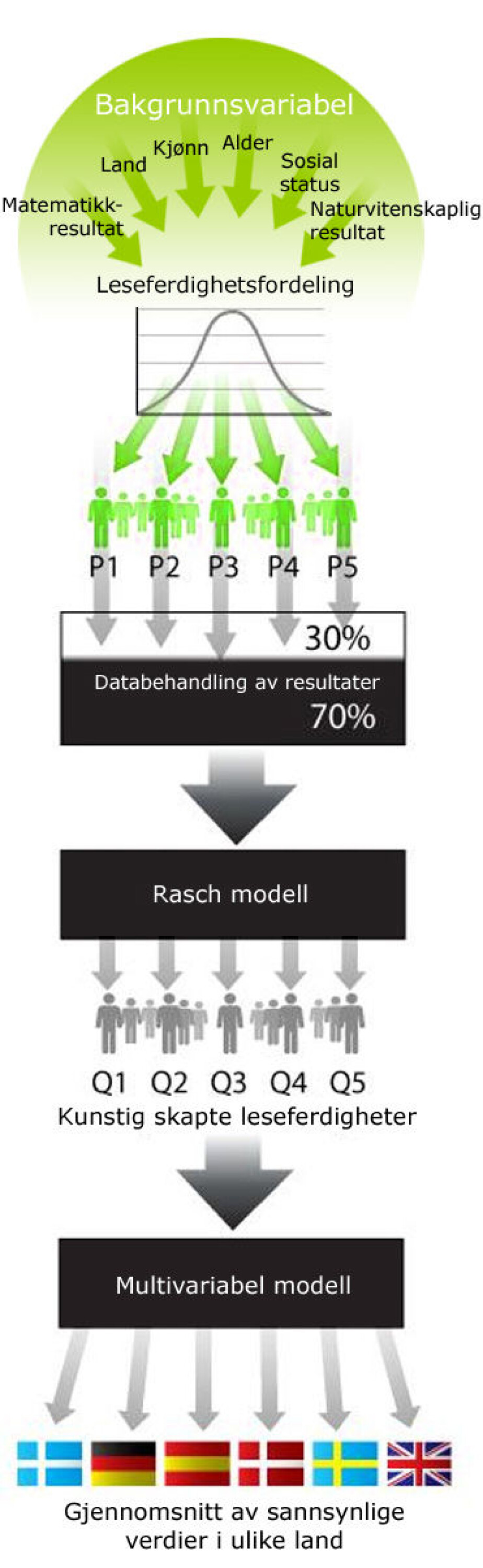
1. Når man har gjennomført PISA-testen og samlet inn elevenes besvarelser i de ulike landene, så starter databehandlingen – det skjer ved hjelp av en avansert datamodell som er bygget av opp forskjellige komponenter.
2. Alle besvarelser lagres i en database sammen med opplysninger om elevenes kjønn, alder, sosiale status. Man antar at elevenes intelligens i et land følger en normalfordeling, hvor det er få med høy intelligens, få med lav intelligens og mange normalbegavede – en antakelse som man i seg selv kan stille spørsmålstegn ved.
De opplysningene kombinerer datamaskinen til et tall som er et mål for hvor dyktige hver og en av elevene er til å lese.
3. Opplysningene blir deretter overført til et nytt dataprogram, laget for å kompensere for at PISA-testen bare tester alle elever i ett av de tre fagene. PISA-undersøkelsen rommer riktignok alltid oppgaver innenfor både lesning, matematikk og naturfag, men hovedfokus ligger på ett av fagene, og det er de få elevene som får besvarer oppgaver innenfor alle tre områder.
Bare ti prosent av deltakerne besvarer alle spørsmål
I 2006 hadde for eksempel testen fokus på naturfag, som samtlige elever ble testet i.
Dessuten fikk den ene halvparten av elevene leseoppgaver, mens den andre halvparten fikk matematikkoppgaver. Under ti prosent av elevene fikk alle oppgaver.
– I rapportene fremgår det ikke hvordan PISA håndterer at man derfor mangler masse data for de fleste elevene og at man derfor er overlatt til gjetninger, sier Kreiner.
En mulighet er at PISA-forskerne setter datamodellen til å gjette hva elevene ville ha svart.
Annonse
En annen mulighet er at de ber datamaskinen konstruere kunstige leseferdigheter for de elevene som har svart på leseoppgaver, og deretter analyserer sammenhengen mellom de kunstige leseferdighetene og andre variabler (blant annet kunstige ferdigheter i matematikk og naturfag).
Til slutt konstruerer forskerne i så fall kunstige leseferdigheter for de elevene som slett ikke har løst noen leseoppgaver – ut fra opplysningene om disse elevenes kunstige matematikk- og naturfagsferdigheter, pluss opplysninger om skole, kjønn, og sosioøkonomisk status.
Argumentet for å bruke denne gjettemetoden er at det tar for lang tid hvis alle elever skal svare på alle spørsmål. Gjettemetoden går ut fra at en dyktig elev i ett fag som regel også er dyktig i alle andre.
Kreiner vet ikke hvilken fremgangsmåtene PISA-forskerne har valgt, fordi modellen bare er beskrevet i svært overfladiske vendinger i de tekniske rapportene.
– Men jeg vil gjette at de har brukt den første. Uansett hvilken av modellene forskerne har valgt, er det betenkelig at datamaskinen gjetter seg frem. Disse gjetningene er fundamentet rankinglisten er basert på, sier Kreiner.
70 prosent skapt av datamaskinene
Av de tallene som kommer ut på den andre siden av boksen, er det bare 30 prosent som stammer fra elevenes faktiske svar. 70 prosent er basert på at datamaskinen har gjettet fram basert på opplysninger om eleven.
– Dette er altså kunstig skapte leseferdigheter, uten fysisk betydning. Tallene kan altså i realiteten ikke beskrives eller forklares; de er bare meningstomme tall, som modellen arbeider videre med, sier Kreiner.
Det siste skrittet i prosessen går ut på å sende tallene over i et ny, såkalt multivariabel modell som er laget til å gi de enkelte landene poeng og plassere dem på en rangstige.
Hvordan modellens siste ledd virker, er heller ikke beskrevet i rapportene.
Man kan likevel teste om modellen arbeider riktig, fordi datamaskinen burde skape den samme rankinglisten uansett hvilken oppgave man lot modellen regne på. Men det kravet lever ikke datamodellen opp til.
– Hvis jeg bruker de oppgavene som danske elever av ukjente årsaker har lettere for å besvare enn elever i andre land, så rykker Danmark opp i toppen av listen. Hvis jeg bruker de oppgavene som danske elever sliter ved, havner vi i bunnen av listen.
Annonse
- Det sier seg selv at begge deler ikke kan være sant, så det er noe helt galt med modellen, konkluderer han.