Denne artikkelen er produsert og finansiert av Universitetet i Oslo - les mer.
Språket forandrer seg hele tiden, og i doktorgraden sin har Andrey Kutuzo jobbet med å se på om det er mulig å oppdage automatisk hvilke ord som endrer betydning over tid.(Illustrasjonsfoto: Glen Carrie / Unsplash)
Telling av ord viser hvordan de endrer betydning over tid
Ord forandrer mening nesten uten at vi legger merke til det. Nå kan algoritmene se når og hvordan.
Språkforskere lar dataprogrammer gå løs på enorme tekstsamlinger for å se hvilke mønstre de oppdager. Den kunstige intelligensen leter rundt i blant annet Wikipedia-tekster og nyhetsartikler.
Algoritmen til Andrey Kutuzov kan finne ut hvilke ord som endrer betydning over tid.
Kutuzov ble imponert da den forsto noe viktig om en opprørsgruppe i den indiske delstaten Assam.
– Algoritmen vet, i den grad vi kan si at en algoritme vet noe, at Taliban og Afghanistan står i samme forhold til hverandre som United Liberation Front of Assam gjør til India, sier Kutuzov, som er postdoktor ved Institutt for informatikk på Universitetet i Oslo.
– Hvis et ord opptrer hyppigere, er dette ordet sannsynligvis blitt viktigere i kulturen, sier Andrey Kutuzov.(Foto: Privat)
Den kunnskapen høres kanskje ikke så imponerende ut, men algoritmen har altså funnet ut dette bare ved å trene seg selv på tekstene den får tilgang til.
– Dette er virkelig en veldig subtil kunnskap. Det betydningsmessige forholdet mellom disse begrepene er langt fra åpenbart, sier Kutuzov.
Tidligere forskning har vist at slike algoritmer , som også kalles datamodeller, fanger opp at det er en lignende sammenheng mellom ordene «søster» og «bror» som det er mellom «mor» og «far».
– Men det var ganske overraskende at informasjon om hvilke væpnede grupper som er aktive i hver enkelt region, kan utledes fra modellen, siden den bare har trent seg på sekvenser av ord, sier Kutuzov.
Språk utvikler seg
Språket forandrer seg hele tiden. I doktorgraden sin har Kutuzov jobbet med å se på om det er mulig å oppdage automatisk hvilke ord som endrer betydning over tid. Han må gjøre maskinene i stand til å løse en slik oppgave på egen hånd.
Det skjer gjennom at algoritmen rangerer ord.
– Fra en liste med for eksempel 100 ord skal den peke på hvilke som har endret seg mer enn de andre, sier han.
– Hvis vi sammenligner det engelske språket på 1800-tallet og det engelske språket i dag, har for eksempel ordet «cell» opplevd sterk endring. Nå brukes ordet om mobiltelefoner, i det 20. århundre kom den biologiske cellen, mens det tidligere mest betydde en klostercelle eller en fengselscelle.
Dette betyr ikke at algoritmene er i stand til å definere betydningen av ordene, slik du finner i en ordbok. De har en annen måte å finne slike sammenhenger på.
Mening er bruk
Kutuzov har med seg tradisjonen fra filosofen Ludwig Wittgenstein, som sa at meningen til et ord bestemmes av hvordan det brukes. Men han er ikke ute etter å definere hva som er riktig eller gal bruk.
– Vi ser bare på dataene uten å si at noe er riktig eller feil. Vi bare observerer.
– Hvis vi antar at betydningen av ord kan utledes fra måten ord brukes på, har vi mange eksempler. Store mengder tekst kan lastes ned fra internett. Vi har mye data, sier Kutuzov.
Annonse
Første trinn er å få maskinene til å se etter hvilke ord som ofte opptrer sammen eller i nærheten av hverandre.
– For å si det litt enkelt, så bare ser vi på hvilke ord som er til venstre og til høyre for disse ordene og hva frekvensene er.
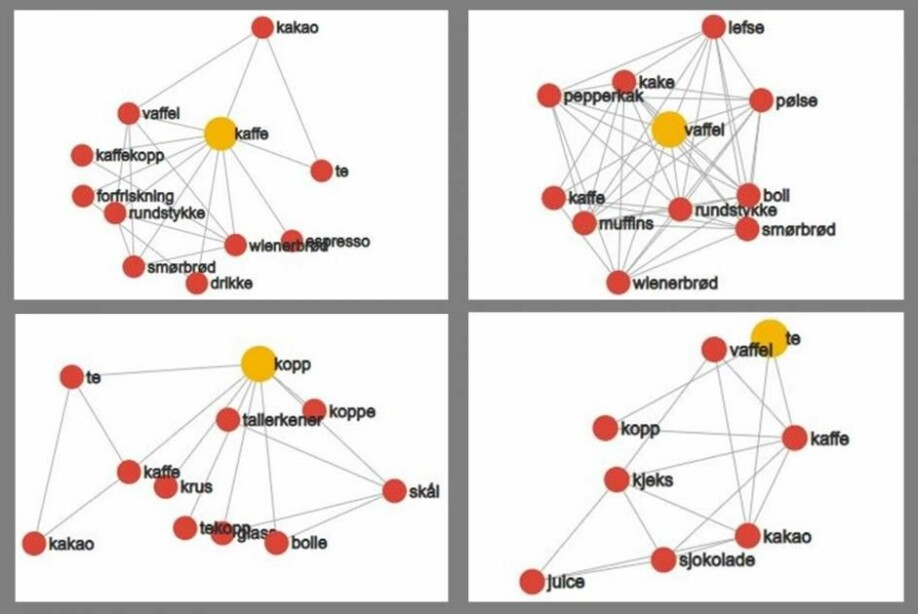
Ordene som oftest opptrer sammen med kaffe, vaffel, kopp og te i Norsk Aviskorpus.(Illustrasjon: WebVectors og Eivind Torgersen / UiO)
Te eller kaffe?
Da vil maskinene fort oppdage at ordet «te» ofte har «kopp» eller «varm» i nærheten av seg. Det samme har selvfølgelig også ordet «kaffe».
– Vi kan se at ordet «te» ligner mer på ordet «kaffe» enn ordet «juice». Modellene fanger at te er noe vi drikker og at det normalt blir servert varmt.
Kanskje vil de se forskjell på te og kaffe hvis de også sjekker for ord som «blader» og «bønner», men Kutuzov er uansett ikke så opptatt av å finne en korrekt beskrivelse av hva te er. Men nå som han har funnet ut hvor ofte to ord opptrer sammen, kan han sammenligne ulike tidsepoker.
Ord som «te», «kaffe» og «kopp» har neppe endret seg så mye. Men med nevnte «celle» er historien en ganske annen.
Professor Lilja Øvrelid har veiledet Kutuzov i arbeidet med doktorgraden.(Foto: Gunhild M . Haugnes / UiO)
– Det samme kan sies om det engelske ordet «broadcast». Det pleide å bety å spre såkorn på bakken. I dag handler det også om TV-programmer og Netflix-serier, sier Kutuzov.
– Vi kan sammenligne endringer i ordbruken og håpe at endringer i bruken betyr endringer i ordets betydning. Men det er vanskelig å fastslå hva som er årsaken og hva som er konsekvensen. Endrer ord betydning på grunn av bruken, eller endres bruken fordi betydningen er endret?
Kutuzov har laget en nettside der du kan leke deg med sammenhengen mellom ord for engelsk og norsk: WebVectors.
Ord som blir brukt ofte, er viktigere for oss
Ordbøker blir mer og mer datadrevne. Forfatterne sjekker gjerne hvor ofte de enkelte ordene opptrer i store tekstsamlinger og finner eksempler på bruk av hvert ord. Men Kutuzovs algoritmer er foreløpig ikke klare til å gi tilfredsstillende definisjoner til slik bruk.
Annonse
– I fremtiden vil vi kanskje se ordbøker der oppføringer blir opprettet ved hjelp av noen av våre språkmodeller. Det ville være fint, sier han.
Men det mangler ikke på bruksområder.
– Hvis du driver med maskinoversettelse, er det lett å argumentere for nytteverdien, sier Kutuzov.
Og hvis du gjør et Google-søk etter et ord som ikke er så vanlig, kan en slik teknologi kommer deg til unnsetning. Hvis du får få treff, vil søkemotoren også vise frem sider som inneholder ord som ofte opptrer sammen med søkeordet ditt.
– Hvis du søker etter «universitet», vil Google sannsynligvis også gi deg dokumenter som inneholder ordene «student» og «professor», hvis det ikke er nok dokumenter med ordet «universitet».
Innenfor relativt ferske forskningsfelt som digital humaniora og det som kalles culturomics, vil kartlegginger som de Kutuzov lager, være veldig nyttige.
– Hvis et ord opptrer hyppigere, er dette ordet sannsynligvis blitt viktigere i kulturen. Vårt arbeid gir disse forskerne et mye kraftigere verktøy for å studere endringer i kultur og samfunn, sier Kutuzov.
Historiske data og moderne AI-forskning
– Bruk av datamaskiner for å spore betydningsendring i språket er blitt gjenstand for økende interesse innenfor språkteknologi de siste ti–tolv årene. Særlig når det gjelder hvordan ord endrer betydning over tid, sier professor Lilja Øvrelid, som har vært veileder for Andrey Kutuzov.
– Interessen for dette fenomenet begrenser seg ikke til språkteknologer, men skjærer på tvers av fag som historie, lingvistikk og digital humaniora, sier Øvrelid.
Hun beskriver Kutuzovs forskning som et svært viktig bidrag til dette forskningsfeltet.
– Han har systematisk sammenlignet en rekke faktorer som kan bidra til maskinlæringsbasert modellering av endring i språk. Kutuzov har benyttet seg av de aller nyeste nevrale maskinlæringsmetodene på feltet og kobler dermed historiske data til moderne AI-forskning, sier Øvrelid.