Utviklingen av norsk språkteknologi har møtt mange motbakker, men nå går det fremover igjen. Blant annet med en talestyrt lommedatamaskin som skal kunne guide turister rundt i Trondheim.
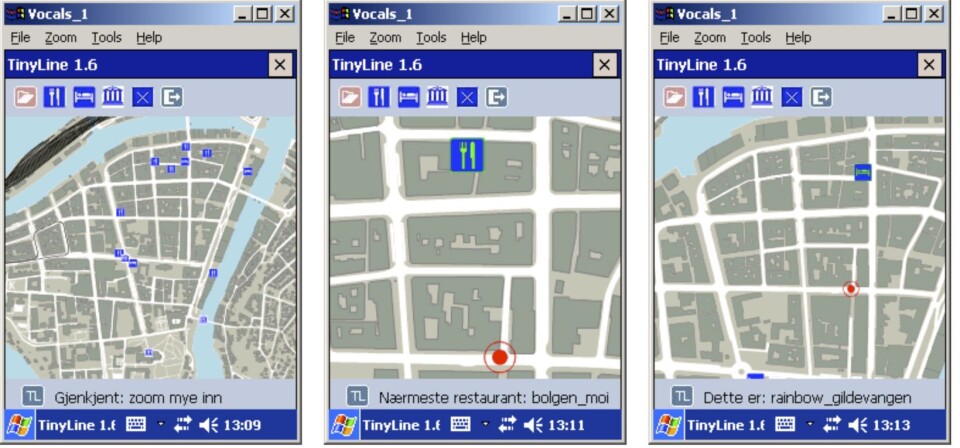
VOCALS-prosjektet har blant annet utviklet en talestyrt applikasjon som kan vise et dynamisk skjermbilde av Trondheim sentrum og gi informasjon om hoteller, restauranter og turistattraksjoner. (Illustrasjon: NTNU)
Voice Centric User Interfaces for Location Based Services
Prosjektet VOCALS (Voice Centric User Interfaces for Location Based Services) ledes av Professor Torbjørn Svendsen ved NTNU. Prosjektet er støttet av Norges forskningsråd gjennom programmene IKT 2010 (Grunnleggende IKT-forskning) og VERDIKT (Kjernekompetanse og verdiskaping i IKT).
Mangelen på språkdata har vært en hovedutfordring for utviklingen av språkteknologi i Norge.
– Det er like komplisert og dyrt å utvikle språkteknologi for et lite språk som norsk, som for de større verdensspråkene. Det gjør ikke saken lettere at vi har to offisielle målformer og et utall dialekter, forteller professor Torbjørn Svendsen ved NTNU.
Utviklingen av norskspråklig talegjenkjenning til et produkt eller en tjeneste ble kraftig forsinket da bedriften Nordisk Språkteknologi (NST) på Voss gikk konkurs i 2003.
NST hadde kommet langt med utvikling av norskspråklige produkter for talegjenkjenning og talesyntese basert på internasjonal teknologi.
Før konkursen hadde NST gjort et stort arbeid med innsamling og lagring av norske språkdata i form av tale- og teksteksempler, men konkursen førte til at dataene ble liggende og støve ned i flere år.
I 2007 gikk universitetene i Bergen, Oslo og Trondheim sammen med IBM og Språkrådet og kjøpte opp serverne, noe som har ført til at språkdataene stort sett er tilgjengelige for forskning igjen.
«The future of computing»
– Den norske språkteknologien er fortsatt i en utviklingsfase, men heller ikke de store verdensspråkene er «i mål». Det trengs flere teknologisprang før datamaskinene er blitt like flinke som mennesker til å gjenkjenne tale.
– Det er fortsatt slik at menneskene er minst ti ganger flinkere enn de beste maskinene og programmene, selv når det gjelder enkle ting som gjenkjenning av tallstrenger av typen kredittkort- eller telefonnummer, oppsummerer Torbjørn Svendsen.
– Språket er en viktig kulturbærer, og det er viktig at vi får utviklet språkteknologi også på norsk, sier Torbjørn Svendsen. Bildet er fra språklaboratoriet på NTNU Dragvoll. (Foto: Rune Petter Ness)
Det er altså et stykke igjen før Microsoft-sjefen Bill Gates’ visjon om at «Speech is the future of computing» er innfridd.
Men en demonstrator som ble utviklet i regi av forskningsprosjektet VOCALS, gir en pekepinn om hvordan fremtiden kommer til å bli også i Norge.
– Utgangspunktet for prosjektet var at det foregår en økende grad av digital konvergens. Det du før bare kunne gjøre på en stor datamaskin, er nå på vei inn også i små lommedatamaskiner (også kalt «Personal Digital Assistant» eller PDA) og til og med mobiltelefoner.
– Dette gjelder ikke minst tilgangen på informasjon via internett. Men det er et problem at disse små maskinene har et dårlig brukergrensesnitt, og det er derfor veldig attraktivt å kunne styre dem helt eller delvis ved hjelp av talekommandoer, forklarer Svendsen.
Som tenkt, så gjort. I VOCALS-prosjektet har Svendsen ledet utviklingen av en enkel talestyrt applikasjon som kan vise et dynamisk skjermbilde av Trondheim sentrum og gi informasjon om blant annet hoteller, restauranter og turistattraksjoner.
Slike systemer utnytter kunnskap fra flere fagfelt, som signalbehandling, statistikk, mønstergjenkjenning og lingvistikk. I såkalte dialogsystemer brukes også naturlig språkbehandling, semantisk analyse og database-søk.
Testing av teknologi
Annonse
Torbjørn Svendsen.
– Det var ikke hensikten å lage noe som skal bli et kommersielt produkt, men å utvikle og teste ny teknologi. Vi har blant annet sett på hvordan talegjenkjenning kan foregå i et område med mye bakgrunnsstøy, som i en gate i Trondheim.
– Vi har også vurdert hvordan man kan organisere slike systemer, og der valgte vi å satse på en distribuert løsning hvor selve talegjenkjenningen og kontakten med databaser foregår på en server som står i trådløs kontakt med PDA-en.
– Dette er en god løsning fordi databehandlingen i de små enhetene vi snakker om har svært begrenset kapasitet, forteller Svendsen.
Forskerne har også testet hvordan dialogen mellom bruker og system kan foregå, enten via «pek og klikk», nedfellsmenyer eller talestyring. Brukerne kan zoome inn eller ut av skjermbildet etter behov.
Språket bærer kulturen
Etter at VOCALS-prosjektet var igangsatt, ble det innledet et samarbeid med et annet forskningsprosjekt som jobbet med å utvikle den første storvokabular talegjenkjenneren på norsk.
En slik talegjenkjenner skal i prinsippet kunne ha et ordforråd minst i samme størrelse som et menneske, noe som kan variere sterkt fra individ til individ. Men innen fagfeltet er 64 000 ord blitt en slags uformell standard, og akseptabel ytelse er omkring 95 prosent nøyaktighet under gitte betingelser.
Det er for øvrig et spesielt problem i norsk at antallet ord i dagligvokabularet er tilnærmet ubegrenset, fordi vi kan skape nye ord ved å sette sammen andre ord. Tenk bare på det norske ordet «talegjenkjenningsteknologi» og den engelske oversettelsen «Speech recognition technology».
Det kan tenkes mange anvendelsesområder for en storvokabular talegjenkjenner, men diktering er ofte etterspurt.
Også innen telekommunikasjon (selvbetjeningstjenester), dialogsystemer, søk i mediedatabaser og hjelpemidler for funksjonshemmede vil dette ha stor nytte. Et eksempel på sistnevnte er teksting av direktesendte TV-programmer for hørselshemmede.
Det finnes foreløpig svært lite av norske produkter basert på språk- eller taleteknologi, men det er blant annet tatt i bruk et dikteringssystem som brukes i sykehussektoren.
– Det er åpenbart behov for langt mer, og både NTNU og Sintef har en rekke aktiviteter på området. Språket er en viktig kulturbærer, og det er viktig at vi får utviklet språkteknologi også på norsk, påpeker Svendsen.