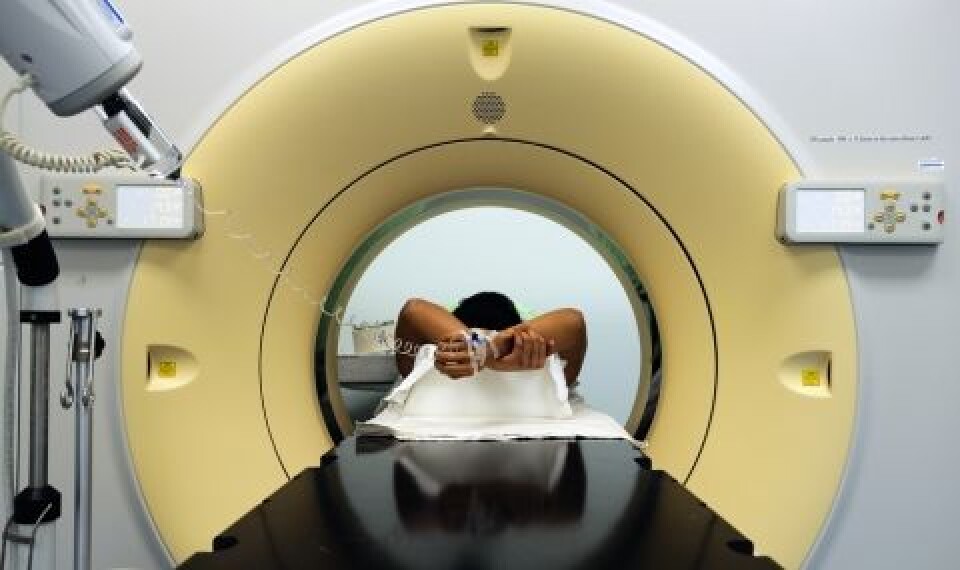
Årlig oppdages rundt 26 000 nye krefttilfeller i Norge. Arvelige tilstander antas å representere fem–ti prosent av alle tilfellene. (Foto: Shutterstock)
Gener
Genene våre er oppskriften på proteiner som trengs for å utføre ulike oppgaver i cellene våre.
Variasjon i arvestoffet i genene kan påvirke proteinenes funksjon og mengden protein som lages, og på den måten gi sykdom.
Det kan også være andre ting som hindrer cellene i å få laget de proteinene de trenger, for eksempel mikroRNA-molekyler som slår av genene.
Biobanker og helseregistre
Norge har en rekke biobanker og helseregistre. I biobankene ligger biologisk materiale som er samlet inn gjennom befolkningsundersøkelser, sykehusopphold, legebesøk eller forskningsprosjekter.
Forskere kan koble data fra det biologiske materialet med personlige data og miljødata som ligger i helseregistre eller pasientjournaler. Slik kan de finne nye sammenhenger mellom molekylære mekanismer og sykdom hos mennesker.
eVITA
Forskningsrådets program for eVitenskap (2006–2015) handler om å utvikle nye arbeidsformer og forskningsmetoder basert på elektronisk infrastruktur for å håndtere store mengder digitale data.
I arvestoffet vårt, DNA, finner vi genene våre. Ved å analysere hvilke varianter syke og friske personer har av ulike gener, har forskere funnet de arvelige faktorene for en rekke sykdommer som brystkreft, lungekreft og diabetes.
Genene utgjør imidlertid bare en til to prosent av arvestoffet vårt.
Så kanskje er det lurt å analysere de andre delene av arvestoffet i jakten på årsakene til at vi utvikler ulike sykdommer?
Små molekyler slår av gener
Det tror i alle fall professor Pål Sætrom ved NTNU. Han leder eGenVar-prosjektet som har støtte fra Forskningsrådet fram til 2015.
Sammen med kollegene har han spesielt konsentrert seg om noen bittesmå molekyler i cellene som kalles mikroRNA-molekyler.
Disse molekylene regulerer aktiviteten til bestemte gener ved å hindre at det blir laget protein fra dem (se faktaboks). De slår rett og slett av genene.
– Vi vil lete etter variasjoner i arvestoffet som gjør at mikroRNA-molekylene ikke får slått av gener. Vi har vist at dette har betydning for utvikling av arvelig brystkreft, forklarer Sætrom.
Nytt dataprogram finner fram
Analyse av blodprøver gir enorme datamengder. (Foto: HUNT)
Forskerne ved NTNU har laget et dataprogram som skal hjelpe dem med å forutse hvilke variasjoner i arvestoffet det er som har betydning for om mikroRNA-molekylene får slått av bestemte gener.
Dataprogrammet gjør det mulig å gjøre virtuelle laboratorieforsøk på datamaskinen. Det er raskere, billigere og reduserer antall virkelige forsøk forskerne må gjøre i laboratoriet.
På denne måten går forskningsprosessen raskere og resultater kan komme raskere til nytte for samfunnet.
– Andre må bekrefte med laboratorieforsøk at variasjonene vi har funnet ved datamaskinen, faktisk har betydning for om mikroRNA-molekylene får slått av genene, sier Sætrom.
– Når det er gjort, kan forskere som jobber med å finne arvelige faktorer for sykdommer, slik som kreft, inkludere variasjonene vi har funnet, i sine analyser. De kan se om det er forskjeller i variantene blant de som har en sykdom og de som ikke har den.
Enorme datamengder
I studiene sine bruker forskerne arvestoff fra biologiske prøver fra HUNT biobank i Levanger. Den inneholder blodprøver fra 65 000 nordtrøndere.
Den typen analyser Sætrom utfører, genererer enorme mengder data. Forskere utfører også mange andre typer analyser på det biologiske materialet i biobankene, for eksempel analyser av proteiner.
Annonse
For biobankene har det blitt en stor utfordring å lagre alle dataene fra de ulike analysene. Det er også krevende å finne ut hvordan dataene skal kunne hentes ut av andre forskere og brukes i videre studier.
Professor Pål Sætrom ved NTNU. (Foto: NTNU)
– Utfordringen er at dataene er generert med forskjellige teknologier fra forskjellige laboratorier. Det er ikke åpenbart hvordan disse dataene skal kombineres på best mulig vis.
– Vi jobber med å lage et system som både holder styr på de ulike dataene og som enkelt kan kombinere disse for nye studier, forklarer Sætrom.
Han sier at det forutsetter at det bygges opp en infrastruktur for sikker lagring av data. Her er i dag NorStore en ressurs, men den infrastrukturen dekker ikke behovet per i dag.
– Vi lager strukturen med HUNT biobank i tankene, men programvaren skal også kunne benyttes av andre biobanker, understreker Sætrom.