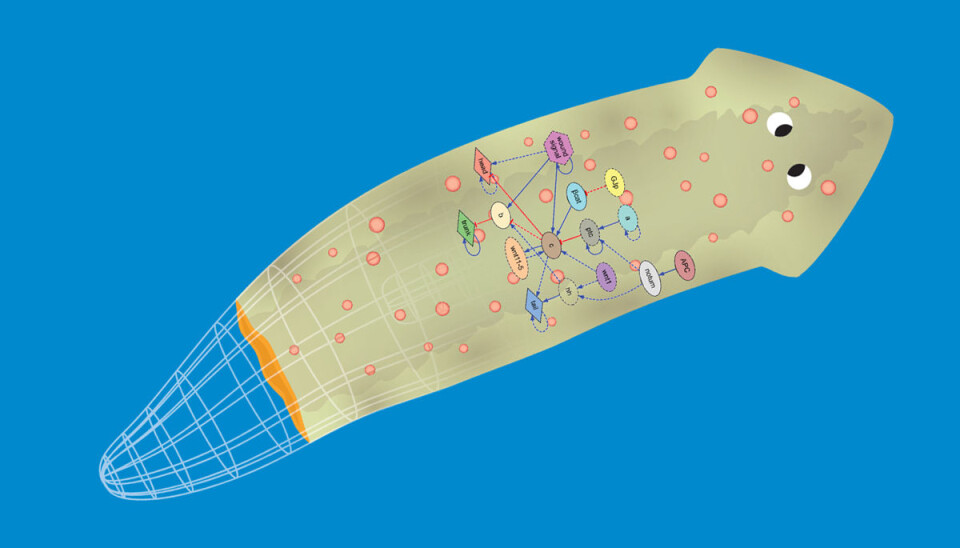
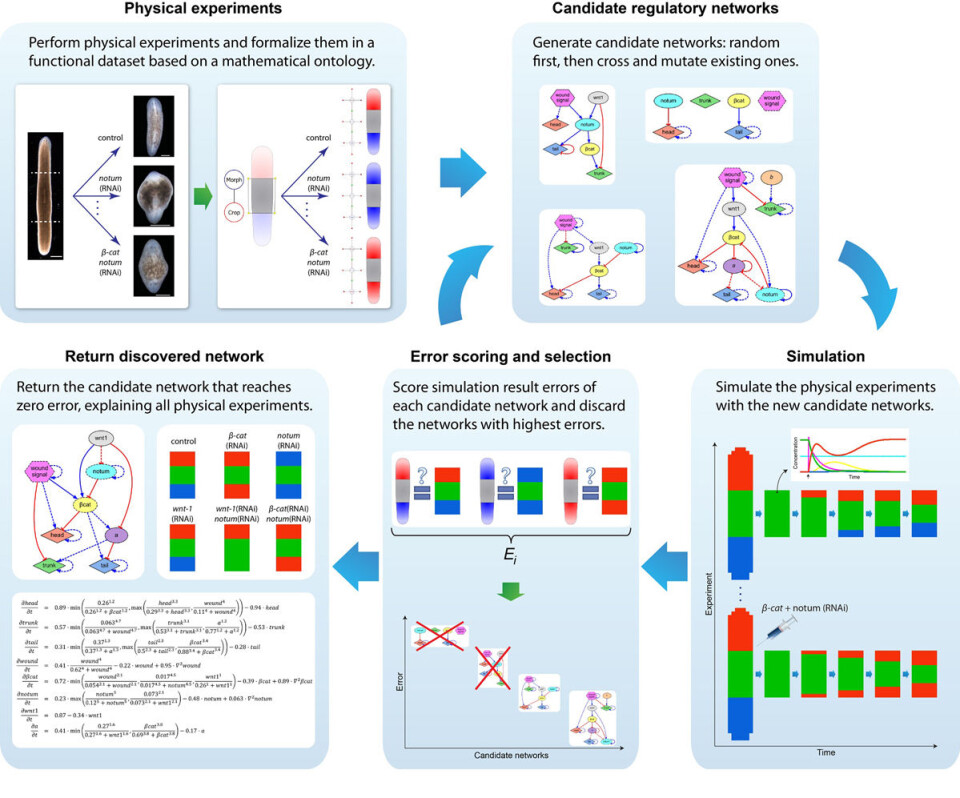
Amerikanske forskere har for første gang brukt kunstig intelligens for å løse et 100 år gammelt mysterium: Hvordan en flatorm kan gjenskape seg selv etter å ha blitt delt opp. (Figur: Levin et al.)
Kunstig intelligens har gjort vitenskapelig oppdagelse
Har funnet ut hvordan flatormen reparerer seg selv.
Denne artikkelen er over ti år gammel og kan inneholde utdatert informasjon.
En kunstig intelligens har klart å finne ut av et 100 år gammelt mysterium: Hvordan flatormer kan gjenskape seg selv etter å ha blitt skåret opp på langs eller tvers.
Det er første gang en kunstig intelligens har gjort en slik oppdagelse, ifølge en melding fra Tufts University, der forskningen er gjort.
Flatormen er så interessant fordi forskerne håper at denne kunnskapen også skal kunne brukes til å gjenskape organer hos mennesker.
Kunnskap om flatormen kan trolig brukes til å utvikle metoder for å dyrke fram nye organer også til mennesker. (Foto: Vengolis, Creative Commons Navngivelse-DelPåSammeVilkår 3.0 Unported)
Mer enn tallknusing
Den kunstige intelligensen har hjulpet til med å bygge bro fra hvordan genene virker på mikronivå til hvordan organene bygges opp i større skala.
Dette arbeidet krever store beregninger, som datamaskiner tradisjonelt har vært gode til. Men det er også et viktig element av kreativitet og intuisjon i arbeidet til den kunstige intelligensen, ifølge meldingen.
Det er spesielt oppsiktsvekkende at den kunstige intelligensen ikke har kommet opp med en innfløkt modell som intet menneske kan få oversikt over. Teorien for hva som skjer i flatormen, er ganske enkel og forståelig.
Fant nye proteiner
Forskerne bak studien i tidsskriftet PLOS Computational Biology er både biologer og informatikere. De laget en datamodell som utviklet seg på noe av den samme måten som livet utvikler seg i evolusjonen.
Etter 42 timers arbeid fant programmet fram til en biologisk modell som stemte med tidligere forskning rundt flatormen. Programmet fant også to proteiner som aldri tidligere var beskrevet i denne forskningen.
Startet på 1970-tallet
Bruk av datamaskiner til problemløsning i forskning er ikke noe nytt. En artikkel i tidsskriftet Science fra høsten 2014 beskriver hvordan forskere allerede på 1970-tallet utviklet systemer med evne til å trekke slutninger av vitenskapelige data.
Ett eksempel var systemet DENDRAL, som analyserte rådata fra massespektrometre og foreslo mulige molekylstrukturer ut fra dette.
Figuren viser datamodellen som ble brukt av forskere ved Tufts University til å finne ut hvordan flatormen klarer å gjenskape seg selv etter å ha blitt delt opp en eller flere ganger. (Foto: (Figur: Daniel Lobo/Michael Levin-Tufts University))
Digitale vitenskapelige assistenter
Annonse
Senere har den akselererende økningen av datakraften fyrt opp under teknikker for maskinlæring som kan arbeide med enorme mengder data, skriver forfatterne i artikkelen i Science.
Nå er også datamaskinene i stand til å arbeide den motsatte veien. De kan utvikle modeller for innsamling av data ut fra hypoteser som de er med på å utvikle.
Datamaskinen vil i framtida også kunne fungere som en intelligent assistent, som sammenfatter og tolker de stadig økende mengdene fagstoff fra tidsskrifter, blogger, diskusjonsfora og etter hvert videoer og bilder.
– Datamaskinen kan bli en reell, om enn underordnet, deltaker i forskerprosessen, skriver forfatterne i Science.
Slike programmer vil igjen stimulere til videreutvikling av kunstig intelligens i en selvforsterkende runddans. Dette kan gi forskere den tverrfaglige oversikten som stadig mer spesialisering truer med å ta fra dem.
– Det er en stadig økende forståelse i akademiske miljøer for at forskere må skaffe seg bred kunnskap og ferdigheter i beregninger og programmering, skriver forfatterne bak artikkelen i Science.