Denne artikkelen er over ti år gammel og kan inneholde utdatert informasjon.
Kognitiv databehangling – eller kunstig intelligens, om du vil – ser ut til å kunne oppdage helt nye enzymer. (Illustrasjonsfoto: Colourbox)
Det nye dataprogrammet leste gjennom 60 000 forskningsartikler, analyserte teksten og fant nye enzymer som kan brukes i kreftbehandlingen.
Av de ti første funnene som programvaren gjorde, har syv vist seg å være riktige.
På enzymjakt
Datagiganten IBM gikk sammen med Baylor College of Medicine i Houston om å utvikle den nye programvaren.
Den ble sluppet løs på mer enn 60 000 artikler som tok for seg p53, et protein med en viktig funksjon for å bekjempe kreft.
Programvaren analyserte setninger i de vitenskapelige artiklene, og ved hjelp av analysen lærte den seg hva som er kjent om proteinkinaser.
Dette er enzymer som reagerer med p53 og endrer hvordan proteinet oppfører seg. Derfor tar mange kreftbehandlinger sikte på å påvirke disse proteinkinasene.
Det som dataprogrammet lærte seg om proteinkinasene, brukte det i neste omgang til å sette opp en liste av andre stoffer som var nevnt i litteraturen, som sannsynligvis var uoppdagede proteinkinaser. De fleste oppdagelsene som er sjekket hittil, viste seg å være korrekte.
Syv av ti
– Vi har testet ti. Syv av dem ser ut til å være virkelige proteinkinaser, sier professor Olivier Lichtarge ved Baylor College of Medicine.
Han presenterte foreløpige funn på et IBM-seminar om kognitiv databehandling – det vil si programvare som etterligner måten menneskehjernen fungerer på, som kan lære og resonnere; også omtalt som kunstig intelligens.
Lichtarge beskrev også en tidligere test av programvaren, der den fikk tilgang til litteratur fra før 2003 for å finne p53-kinaser. Programmet fant sju av de ni kinasene som er oppdaget siden 2003.
Finner stoffene raskere
– p53-biologi er sentral for alle typer sykdom, sa Lichtarge, ifølge MIT Technology Review.
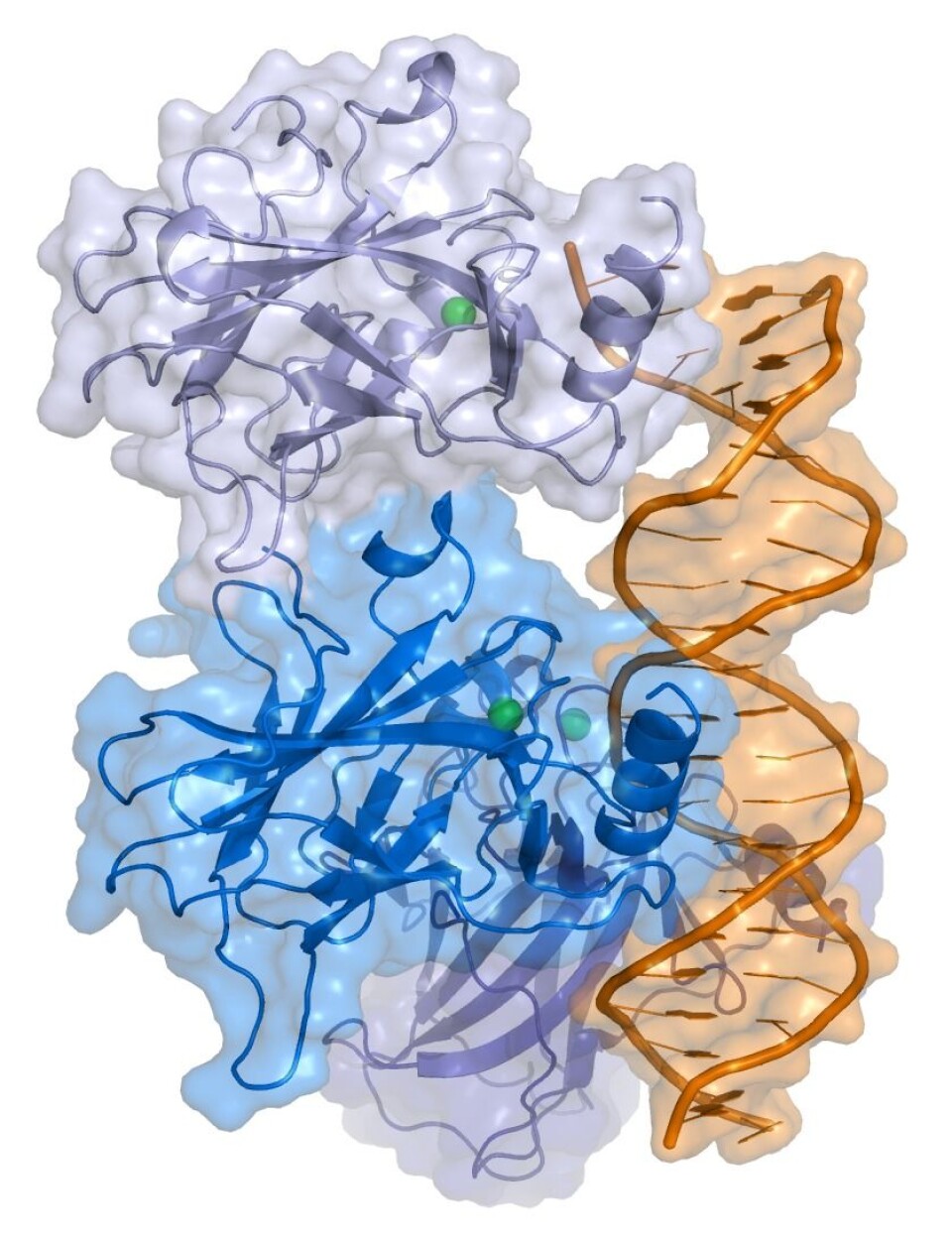
p53 er et protein som holder tilbake svulster, og dermed er viktig for å forebygge kreft. Her er det tegnet sammen med DNA. (Foto: (Illustrasjon: Thomas Splettstößer, Wikimedia Commons))
I dag oppdages det gjennomsnittlig én ny proteinkinase i året. Med denne sorten programvare kan de finnes langt raskere, mener Lichtarge.
På seminaret fortalte han at selv om programmet var satt opp for å se etter proteinkinaser, ser det også ut til at det er i stand til å finne andre enzymer som hittil ikke er oppdaget, og andre typer protein som kan påvirke p53.
Overfor forskning.no understreker Olivier Lichtarge at det er snakk om foreløpige funn på et tidlig stadium, og at han la dem frem uten å være klar over at det var en journalist blant tilhørerne.
– Jeg har ikke noen svar å gi deg nå. Grunnen er, og jeg vil gjerne understreke det igjen nå på samme måte som jeg gjorde i presentasjonen min, at resultatene er foreløpige og at de trenger mer testing og fagfellevurdering før jeg vet hvor nyttige de er, sier Lichtarge.
Annonse
Tekstanalyserer medisin
MIT Technology Review forteller hvordan legemiddelindustrien bruker tekstanalyseverktøy for å grave i publikasjoner, patenter og molekyl-databaser. For eksempel kan et selskap som forsøker å finne en ny malariamedisin, bruke tekstanalyse for å finne molekyler med egenskaper som ligner de medisinene som allerede finnes på markedet.
Fordi programvaren kan søke bredere, kan den finne omtale av molekyler i artikler eller patenter der mennesker ville oversett den.
Forskningslitteraturen er så omfattende at det er umulig for en spesialist å lese gjennom alt som kan komme til nytte. I fjor ble det lagt over en million nye artikler til det amerikanske nasjonalbibliotekets database over biomedisinske forskningsartikler, Medline.
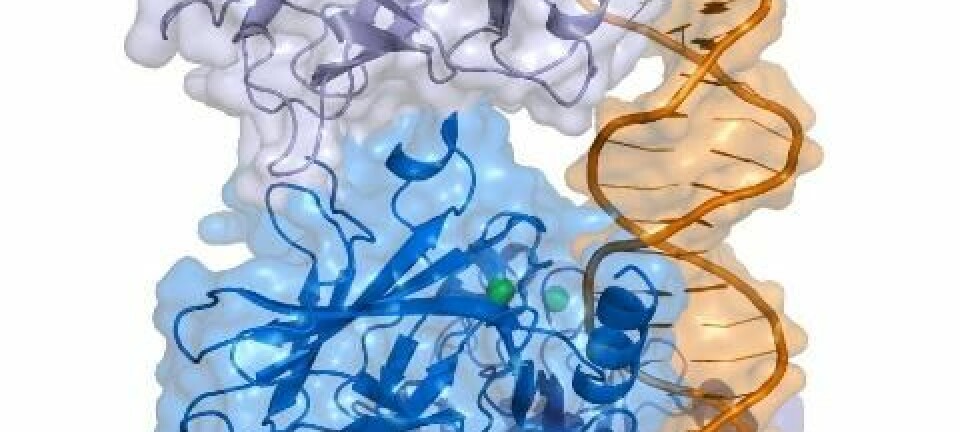
I første omgang er det stoffer som kan brukes i arbeidet med kreftmedisin, som er identifisert av tekstanalyseverktøyet. (Foto: (Illustrasjon: Colourbox))
Nå omfatter Medline 23 millioner artikler, skriver MIT Technology Review. Informasjon som er viktig for ett tema, kan være skjult i en bisetning i en artikkel som egentlig handler om et helt annet tema.
– Interessant metode
Norske forskere ser på tekstanalysen som en interessant metode. – I og med at det ikke er gjort noen kontrollforsøk ennå, så er det jo endel å utsette på dette metodemessig, og for tidlig å konkludere.
Men det er en interessant idé å bruke automatisk tekstanalyse til å finne ut hva som er mest signifikant i den enorme skogen av funn, sier lektor Gisle Hannemyr ved Universitetet i Oslo.
Han kan ikke si ennå om dette er veien å gå for forskning i fremtiden:
– Den måten forskning fungerer på, er at vi prøver ut masse forskjellige ting, og så konstruerer etterprøvbare og reproduserbare forsøk som kan falsifisere eller bekrefte en hypotese. Men hypotesen er åpenbar: At maskinelle analyser av et stort antall artikler vil klare å finne frem til lovende stoffer som mennesker ikke klarer å finne i samme grad, sier Hannemyr.
Mest til tekstsøk
Professor Jan Tore Lønning, som leder forskningsgruppen for språkteknologi ved Universitetet i Oslo, forteller at tekstverktøy allerede brukes i forskningen, men mer til søk enn til analyse:
Annonse
– I medisin og biologi kan det brukes for å finne frem i forskningsartikler. Det er ikke alltid du finner ting ut fra tittelen på artikkelen. Derfor er det forskjellige måter å søke gjennom store baser på, for å finne det som er relevant, sier han.
Derimot er det nytt å bruke tekstanalyse for å forsøke å komme frem til andre slutninger og trekke ut andre mønster enn det de opprinnelige artiklene har gjort.
Google følger epidemiene
Et annet eksempel på tekstsøk som verktøy i medisinen, er de årlige influensaepidemiene. – Google-data kan brukes til å spore hvordan en epidemi sprer seg, forklarer Lønning.
Følger du aktiviteten på nett – nyheter, blogger, tweets – så kan du følge langt bedre med på utviklingen enn om du venter på de offisielle rapportene. De fleste vil fortelle for eksempel på bloggen sin, Twitter eller Facebook at de har influensa lenge før det kommer i helsestatistikken.
– Data på nettet ligger foran offisiell rapportering av helsestatistikk, som først må samles inn fra legene og bearbeides, sier Jan Tore Lønning.