Avdelingsdirektør ved Folkehelseinstituttet Line Vold blir intervjuet om koronasituasjonen etter en pressekonferanse. De som sitter og regner på hvordan sykdommen sprer seg i befolkningen er en gjeng med elleve forskere i modelleringsgruppa til Folkehelseinstituttet.(Foto: Håkon Mosvold Larsen / NTB scanpix)
Smittetallet R: Slik regner Folkehelseinstituttet ut hvordan koronaviruset sprer seg
Under covid-19-pandemien har mange av oss fått et forhold til smittetallet R. Det kan virke som om alt står og faller på dette tallet.
For holder det seg under 1 blir det gradvis færre og færre som får sykdommen, har vi lært. Mens hvis det blir høyere enn 1, kan flere og flere bli smittet.
forskning.no har tatt en prat med Solveig Engebretsen, en av forskerne i modelleringsgruppa til Folkehelseinstituttet. Vi ville prøve å forstå hvordan de matematiske modellene de bruker faktisk fungerer.
Og ikke minst hvilken verdi slike modeller av covid-19 faktisk har − når det fortsatt er så mye vi ikke vet om hvordan sykdommen sprer seg.
Solveig Engebretsen lagde en matematisk modell for influensasmitte i Bangladesh under doktorgraden sin, basert på mobildata fra Telenor. Derfor har hun blitt sentral i arbeidet med å modellere smittespredningen av koronaviruset.(Foto: UiO)
Etterligner smittespredningen på datamaskinen
Engebretsen forteller at den matematiske modellen de bruker ikke regner ut smittetallet R direkte.
Men tallene forskerne får ut fra modellen, kan plugges inn i en formel som gir smittetallet vi har blitt vant til å høre om under koronapandemien.
− Det er smittetallet R som er mest populært å rapportere ut, så det er det vi oppgir, sier forskeren som er ansatt ved Norsk Regnesentral.
Men hun poengterer at det viktigste med den matematiske modellen ikke nødvendigvis er selve smittetallet R. Derimot er forskernes viktigste mål å lage en god virtuell etterligning av hvordan smitten sprer seg.
For hvis modellen på datamaskinen fanger opp essensen i hvordan smitten sprer seg, kan den brukes til å se inn i fremtiden.
− Noe av det som er viktig, er å kunne gi estimater på hvor mange sykehusinnleggelser det kommer til å bli og hvor mange som vil trenge respiratorbehandling, sier Engebretsen.
Flytter virtuelle nordmenn hver sjette time
Så hvordan fungerer egentlig denne matematiske modellen?
Enkelt sagt handler det om å la smitten gå sin gang i befolkningen – på datamaskinen.
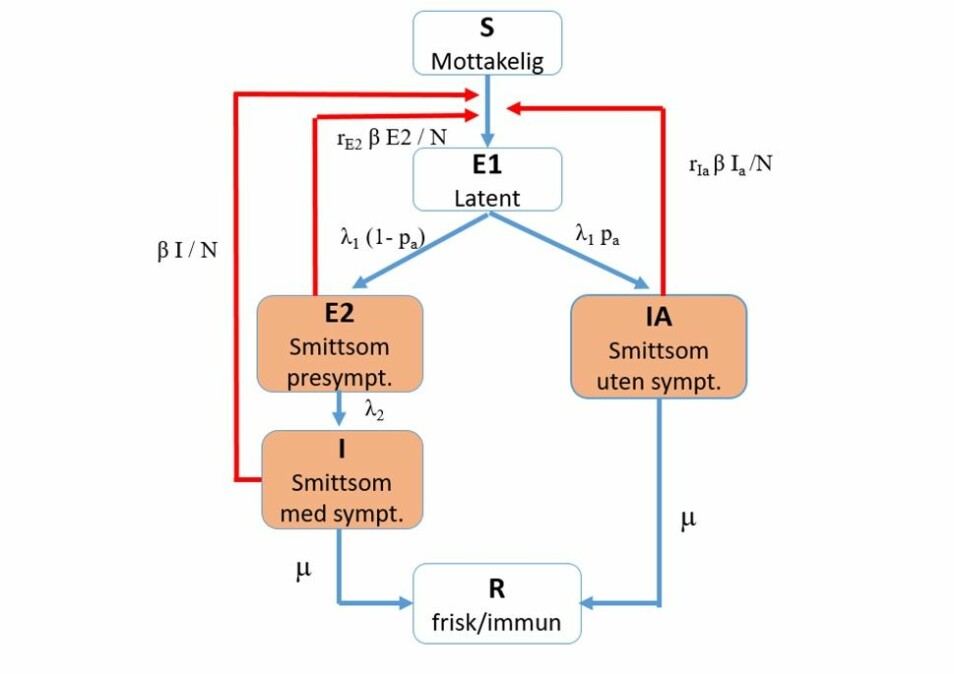
Innenfor hver kommune kan innbyggerne havne i seks smittekategorier, hvor de er smittsomme i tre av dem.
Forskerne skiller nemlig mellom de som har covid-19 med symptomer og de som får sykdommen uten symptomer. Det er fordi en koronainfeksjon med symptomer trolig smitter lettere enn når viruset ikke gir noen symptomer.
For hver kommune har forskerne da en matematisk modell som ser slik ut:
Slik sprer koronasmitten seg mellom folk ifølge den matematiske modellen de bruker ved Folkehelseinstituttet.(Figur: Folkehelseinstiuttet)
Du trenger ikke bry deg om alle symbolene, men legg spesielt merke til de røde pilene.
Annonse
Forskerne prøver å regne ut hvor ofte smitten sprer seg langs disse pilene. Altså fra folk som er i de tre smittsomme kategoriene (oransje bokser) til de friske som er i mottakelige for smitte.
Du kan også legge merke til symbolet β (beta) langs de røde pilene. Det kommer vi nemlig tilbake til.
Mobildata fra Telenor
I januar, før epidemien startet, var alle innbyggerne i hver kommune i kategorien mottakelig.
Da folk begynte å komme hjem fra reise til utlandet med smitte, plasserte forskerne dem i en av de smittebærende kategoriene (markert i oransje i figuren) i de kommunene de reiste hjem til.
Så lar forskerne smitten gå sin gang i de virtuelle kommunene og ser hva som skjer.
Forskerne oppdaterer modellen hver sjette time med data fra Telenor om hvor mange nordmenn som flytter på seg fra én kommune til en annen.
Det betyr at de fiktive menneskene blir flyttet fra for eksempel Oslo-modellen til Trondheim-modellen. Hvis Oslo-borgeren er smittet, kommer det en ny smittet person inn i Trondheim-modellen som kan gjøre at smitten øker der.
Mange antagelser
Så hvordan henger alt dette sammen med smittetallet R?
Formelen for smittetallet R er en kombinasjon av det som skjer langs pilene som går ut fra de oransje boksene i figuren, sier Engebretsen.
Altså hvor mange du typisk smitter i de tre forskjellige smittekategoriene: før du får symptomer, når du har symptomer eller hvis du har sykdommen uten å få symptomer i det hele tatt.
Annonse
For å gå dypt inn i materien er det altså verdien β (beta) som forskerne regner ut fra smittemodellen. Dette tallet sier noe både om hvor smittsom sykdommen er og hvor mye kontakt vi har med hverandre i befolkningen.
− Det er egentlig beta vi estimerer. Så bruker vi det estimatet til å regne ut smittetallet R for modellen, sier Engebretsen.
Begynner på nytt for hver simulering
Alle de andre symbolene langs pilene i figuren er tall som forskerne henter fra både norsk og internasjonal forskning på koronaviruset.
Disse tallene beskriver for eksempel hvor mange dager folk er i hver smittekategori. Eller hvor stor andel av de som blir smittet som får sykdommen helt uten symptomer. Forskerne oppdaterer disse tallene når det kommer ny kunnskap om viruset.
Men siden forskerne ikke vet helt sikkert hva alle tallene i figuren er – og at sykdomsforløpet varierer fra person til person – har forskerne introdusert en del tilfeldigheter i modellen.
Så derfor gjør de mange simuleringer av hvordan smitten har spredd seg i Norge, som gir litt forskjellig resultat hver gang.
For hver ny simulering starter forskerne helt på begynnelsen fra 1. januar 2020. Og så ser de hva som skjer med smitten i befolkningen.
Usikker beregning
Men med så mange usikre tall og så mange antagelser, kan vi egentlig stole på en slik modell av koronaviruset?
− Nasjonalt vil jeg si vi har ganske gode estimater, sier Engebretsen.
Hun legger vekt på resultatene de får ut av den matematiske modellen. For når de bruker modellene til å forutse hvor mange som vil havne på sykehus, stemmer de godt overens med virkeligheten. Det tyder på at modellen fanger opp det viktigste, sier forskeren.
Annonse
Samtidig mener hun det er en avsporing å snakke om et presist smittetall R, men at vi heller må snakke om hele usikkerhetsintervallet.
− Vi prøver å understreke at vi må se på hele intervallet og at det er veldig stor usikkerhet. Så den gjennomsnittsverdien har ikke så mye å si når det er så stor usikkerhet, sier Engebretsen.
Vil ikke overtilpasse modellen til virkeligheten
Forskerne bruker også informasjon om hvor mange som faktisk havner på sykehus med covid-19 i den virkelige verden til å justere den matematiske smittemodellen sin. Nærmere bestemt for å regne ut smittsomheten − beta.
Men Engebretsen legger vekt på at de ikke vil justere modellen for mye etter dataene.
Å tilpasse en modell for mye etter dataene kan bli som at vi tolker en rekordkald mai her i Norge som at vi er på vei inn i en ny istid.
Så for å ha en robust smittemodell, som kan spå noe om hvor stor belastning helsevesenet vil få i fremtiden, må ikke modellen være overtilpasset til sykehusinnleggelsene, sier Engebretsen.
− Vi vil ha en modell som følger sykehusinnleggelsene godt uten å være for overtilpasset til dataene. Ellers får vi en modell som passer veldig godt til de dataene vi har, men som ikke er generell nok for nye data som vi ikke har sett ennå, sier Engebretsen.
Låste smittetall
Dette er en av grunnene til at forskerne i modellgruppa til Folkehelseinstituttet har valgt å ikke la smittetallet variere fra dag til dag.
Derimot opererer de med tre ulike smittetall per dags dato.
Det første smittetallet gjelder fra epidemien startet frem til de strenge tiltakene ble satt inn. Det andre smittetallet gjelder frem til Norge begynte å åpne opp igjen. Mens det tredje smittetallet gjelder fra landet begynte å åpne opp igjen.
Annonse
I selve modellen er det altså egentlig tallet beta som er låst på denne måten.
Kritikk fra forskere ved NTNU og UiT
At de låser smittetallet, har Folkehelseinsituttet fått kritikk for, blant annet i denne kronikken i VG av Dag Svanæs, forsker ved NTNU.
Smittetallet som Folkehelseinstituttet rapporterer, sier veldig lite om hvordan pandemien sprer seg i befolkningen akkurat nå, ifølge Svanæs.
Og to forskere ved UiT – Norges arktiske universitet, har selv regnet ut at smittetallet R er over 1, som de de beskriver i et forskningsnotat (PDF).
Disse forskerne mener altså at smittetallet bør få variere mye friere i modellen.
Engebretsen er enig i at å låse smittetallet, eller altså tallet beta, er en forenkling.
Men hun presiserer også at alle modeller er forenklinger fordi de baserer seg på ulike antagelser om virkeligheten.
− Man kan kanskje si at modellen vår er enkel fordi vi antar konstante verdier mellom datoene vi endrer den, men den tilpasser jo godt kurven med sykehusinnleggelser, sier forskeren.
Så lenge modellen er en god beskrivelse av det som faktisk skjer, mener hun at det er en styrke at det er en enkel modell. Og at en mer fleksibel modell ikke nødvendigvis vil gi riktigere svar.
Bare Norge har denne modellen
Så hvorfor er det ikke noen fasit på hvordan vi skal regne ut smittetallet?
Lederen av modellgruppa ved Folkehelseinstituttet, Birgitte Freiesleben de Blasio, holdt et foredrag om arbeidet de gjør ved Norsk Vitenskaps-Akademi 23. april. Da ble hun spurt om det er noen andre land som bruker akkurat denne modellen til å regne ut hvordan smitten sprer seg.
− Modellen er utviklet for Norge, og det er bare oss som bruker denne modellen. Men vi møtes jevnlig med modelleringsgruppene fra Folkehelseinstituttene i de andre nordiske landene, svarte de Blasio.
Hun sa også at av de nordiske landene sine modeller, ligner den norske mest på den de bruker i Danmark.
Til forskning.no sier også de Blasio at modelleringsgruppa ved Folkehelseinstituttet jobber med flere forskjellige modeller. Blant annet har de en annen modell de justerer etter hvor mange som får påvist viruset med laboratorietester.
− Folkehelseinstituttet gjør en samlet vurdering av situasjonen basert på resultater fra modellering og mange typer data, inkludert konsultasjoner hos fastleger, laboratoriedata, dødsfall, overvåking i sykehus og sykehjem, og resultater tverrsnittstudier av befolkningen, sier de Blasio.