Denne artikkelen er over ti år gammel og kan inneholde utdatert informasjon.
Go er et av verdens eldste brettspill som fortsatt spilles i dag. Spillet skal være mer enn 2500 år gammelt og det oppsto i Kina. Spillet er også stort i Japan og Korea.
Det kan se ganske enkelt ut. Spillet består av et rutenett og svarte og hvite brikker, men spillet skjuler ekstremt dype strategier. Det er kanskje en av grunnene til at spillet fortsatt spilles etter tusenvis av år.
Nå har en internasjonal forskergruppe laget en kunstig intelligens som spiller go. Men dette programmet er så kraftig at det har klart å slå den europeiske mesteren Fan Hui i fem av fem spill.
Dette er første gang en profesjonell spiller har tapt mot en datamaskin i go, uten handicap eller andre modifiserte regler, ifølge tidsskriftet Nature.
– Dette synes jeg er veldig imponerende, sier Anders Kofod-Petersen til forskning.no.
Han er visedirektør ved Alexandrainstituttet i Danmark og professor II på institutt for datateknikk og informasjonsvitenskap på NTNU. Han har ikke deltatt i den nye studien.
– Go er spesielt vanskelig for datamaskiner, så det har vært trøblete å få programmer til å spille like godt som mennesker.
Go-reglene høres ganske enkle ut. Spillet foregår på et brett med 19x19 ruter, og to spillere bruker annenhver tur til å sette ut en stein der linjene krysser hverandre i rutenettet. Steinene flyttes ikke etter at de er satt ut. En spiller er hvit, og den andre er svart.
Hvis en stein blir omringet av steiner av den andre fargen, blir den fangede brikken fjernet fra spillet. Målet med spillet er å kontrollere mer enn halvparten av brettet.
Go er et spill med det spillteoretikerne kaller perfekt informasjon. Spillerne vet alltid hva som har skjedd i løpet av spillet, og hva den andre har gjort i sine trekk. Sjakk er også et spill med perfekt informasjon. Det er mange flere regler, som du kan lese om her.
Den kinesiske spilleren Gu Li spiller mot Lee Sedol i 2009. Lee Sedol skal prøve seg mot programmet i løpet av vinteren. (Foto: Corbis/NTB Scanpix)
Men de enkle reglene gjør også spillet ekstremt komplisert. Hvis den hvite spilleren plasserer brikken sin et sted, har svart hundrevis av valgmuligheter når det er hans tur. Det samme gjelder for hvit igjen, og etter hvert blir det milliarder av mulige spill som kan utfolde seg.
På grunn av kompleksiteten blir go gjerne kalt matematikernes spill.
– Det er flere mulige kombinasjoner på brettet enn det er atomer i universet, sier Demis Hassabis til Nature i denne videoen. Han er kunstig intelligens-forsker ved selskapet Google Deepmind, som har utviklet programmet.
Annonse
Det er teoretisk mulig at et go-spill varer i så mange trekk at det tar milliarder av år å bli ferdig med ett eneste spill.
– Menneskelige spillere kan aldri teste ut alle disse kombinasjonene. Det er så mange at vi må velge og justere vinnende strategier for å prøve å slå motstanderen, sier Kofod-Petersen til forskning.no.
Vi må også justere spillet og veie mange strategier opp mot hverandre, mens vi hele tiden oppdaterer informasjon om hva som skjer på brettet.
– Det er et veldig intuitivt spill. Hvis du spør en dyktig go-spiller om hvorfor han gjorde det trekket, svarer de ofte at det bare føltes riktig, sier Demis Hassabis.
Dataprogrammer er veldig flinke til å regne, men de er tradisjonelt ikke flinke til å velge gode strategier. I et sjakk- eller go-program virker det kanskje naturlig at programmet bruker rå styrke for å slå sin menneskelige motspiller. Det betyr at datamaskinen ser hvilket trekk som blir gjort, og så begynner å regne gjennom alle tenkelige muligheter for å analysere hvilken vei spillet tar og hvordan det eventuelt slutter.
– Men dette fungerer veldig dårlig i go på grunn av den overveldende mengden kombinasjoner, sier Kofod-Petersen.
Sjakk-datamaskiner kan også vurdere forskjellige strategier, og det er slik de slår mennesker. Men mulighetene i sjakk er mye færre enn i go, derfor har det blitt sett på som veldig vanskelig å lage et dyktig go-program. Flere muligheter betyr massevis av nye strategier.
Så hvordan har forskerne klart å lage et dataprogram som faktisk klarer å slå profesjonelle go-spillere?
Selvlærende
Svaret ligger i kunstige nerve-nettverk. Forskerne bruker en metode som aper etter menneskehjernen, hvor simulerte nevroner blir koblet sammen. Disse nettverkene er delvis selvlærende, og forskerne forsøker å få maskinen til å spille på en mer menneskelig måte.
– Vi har forstått at det kan være nyttig å lage kunstige nevrale nettverk siden 1960-tallet, men det har ikke vært nok datakraft før nå, forteller Kofod-Petersen.
– Systemene er ekstremt mye enklere enn menneskehjernen, men det fungerer prinsipielt på samme måte.
Forskerne kan vise dette nettverket eksempler på go-spill, slik at systemet lærer selv hvordan det skal spille smart. I begynnelsen observerte programmet, som heter Alphago, mennesker som spilte go.
Etter hvert ble datamaskinen satt til å spille mot seg selv. Etter massevis av spill begynner programmet å lære seg hvilke strategier som fungerer i forskjellige situasjoner.
Data-nevronene tilpasser seg hva som blir puttet inn i maskinen, og kan dermed gjøre mer nøyaktige gjetninger etter hvert som den lærer. Ansikts- og stemmegjenkjenning er andrre eksempler på teknologier som bruker slike kunstige nevrale nettverk.
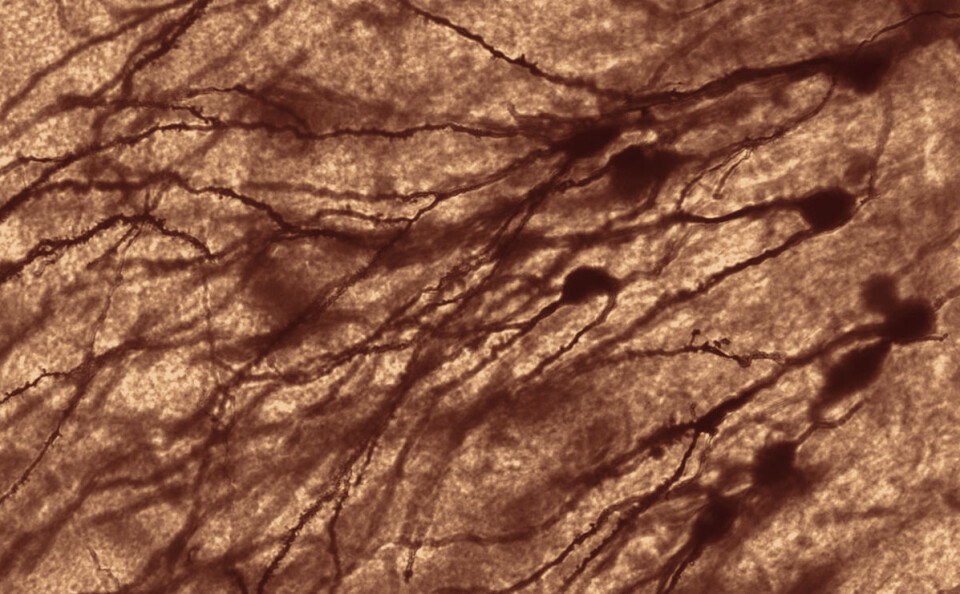
Hjerneceller og nevroner. Datamaskinene er fortsatt langt unna dette, men det kommer seg. Det mest avanserte kunstige nevrale nettverket tilsvarer en kubikkcentimeter av en ekte hjerne. (Foto: MethoxyRoxy, Creative Commons Attribution-Share Alike 2.5 Generic license, fargelagt av forskning.no)
Flere nettverk
Alphago består av forskjellige nevrale nettverk som gjør forskjellige oppgaver. Det ene nettet kalles «policy network», og reduserer det store antallet mulige trekk til noen få, lovende trekk.
Det andre nettet kalles «value network», og har som oppgave å finregne på forskjellige muligheter som ligger i disse lovende trekkene. Den regner ikke gjennom hundrevis av trekk, men nok til å kunne gjøre en vurdering av hvordan det er best å fortsette spillet.
– Vi tror at dette ligner på hvordan mennesker spiller slike spill, sier forsker David Silver i den samme Nature-videoen. Han er hovedforfatter av artikkelen.
Med mer læring og mer datakraft tror han at programmet kan bli bedre enn noe menneske.
Programmet vinner mer enn 99 prosent av spillene mot andre dataprogrammer. Til nå har også programmet altså klart å slå den europeiske mesteren.
Den neste utfordreren blir koreanske Lee Sedol. Han regnes som en av verdens beste spillere gjennom det siste tiåret.
Annonse
– Jeg er privilegert som får spille dette spillet. Jeg hører at programmet blir sterkere og sterkere, men jeg tror jeg skal vinne denne gangen, sier han til Nature.
Kampen skal spilles i mars.
Referanse:
Silver mfl: Mastering the game of Go with deep neural networks and tree search. Nature, januar 2016. DOI: 10.1038/nature16961. Sammendrag